A Hybrid Context -Knowledge Representation Model for Arabic Next Word Prediction
DOI:
https://doi.org/10.29304/jqcsm.2026.18.12448Keywords:
Arabic text processing, AraBERT, Knowledge Graph, , Language modeling, Next word predictionAbstract
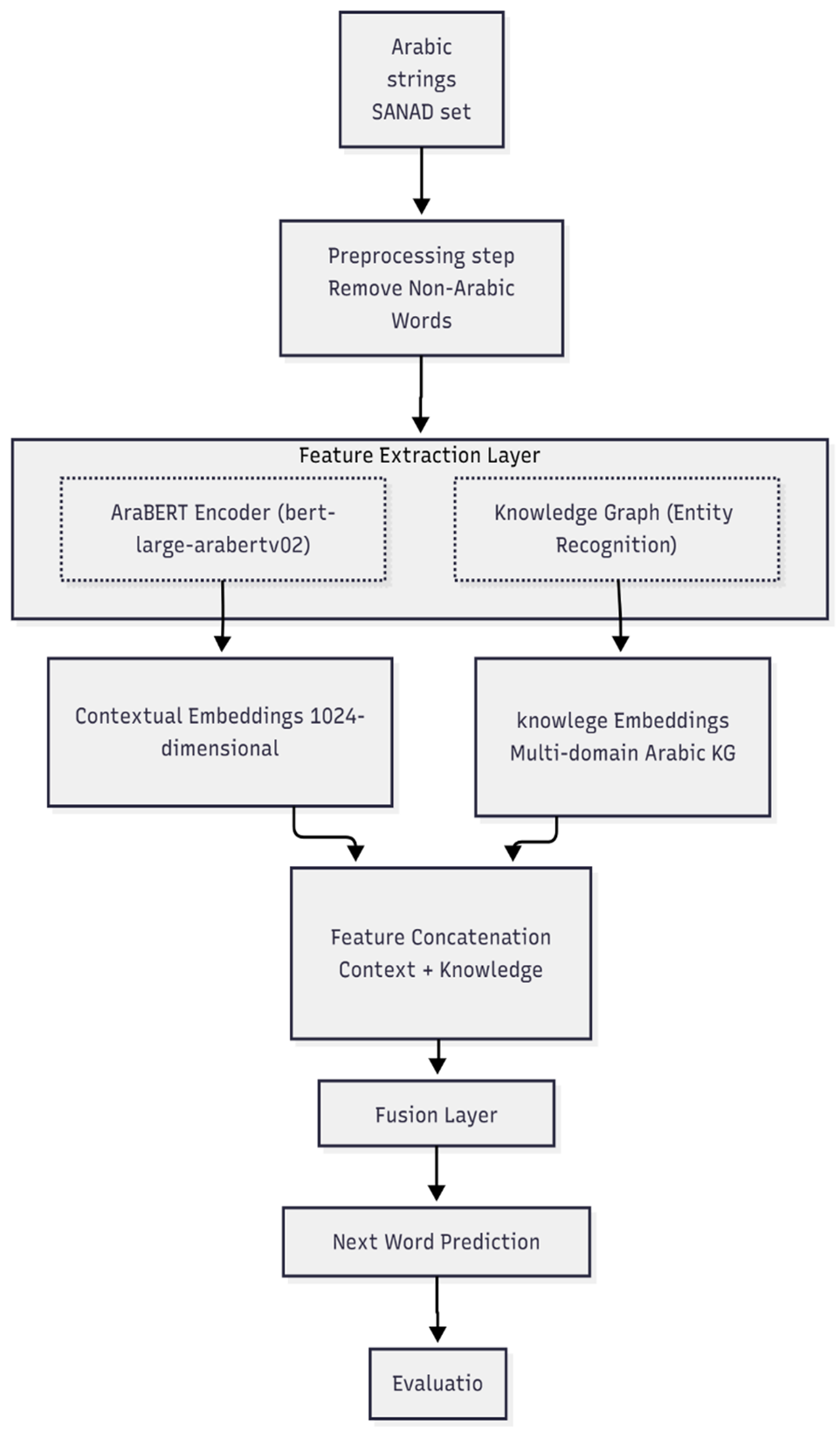
One of the controversial topics that has been raised in recent decades. Several approaches involving deep learning and machine learning was implemented to investing in the field of next word prediction in multiple language. In Arabic contexts, this topic is still challenges and in its early stages which need more investigation researches. this field suffers from lakes of robust model that designed specifically for predicted next Arabic word and high-quality dataset that used to develop this domain. This paper proposed a parallel hybrid model (AraBERT- knowledge graph) that augmented the pre-trained AraBERT model with knowledge graph to significantly enhanced next word prediction in Arabic corpus. The constructed of the proposed model involved integrating the AraBERT’s contextual vectors with entities of embedding of knowledge graph (KG). The SANAD dataset (195k articles) was used train this model. The model achieved an accuracy of 90% and an F1-score of 91% which outperformed several of fine adaption baseline models including AraGPT-2 (84.8) and AraBERT (82.6%). The significant improvement in results indicates that the combining of contextual and knowledge based has a promising direction for advancing several of Arabic language application including Arabic text prediction, understanding, and auto-generation, and other NLP application.
Downloads
References
K. Shakhovska, I. Dumyn, N. Kryvinska, and M. K. Kagita, “An Approach for a Next‐Word Prediction for Ukrainian Language,” Wirel. Commun. Mob. Comput., vol. 2021, no. 1, Jan. 2021, doi: 10.1155/2021/5886119.
R. Sharma, N. Goel, N. Aggarwal, P. Kaur, and C. Prakash, “Next Word Prediction in Hindi Using Deep Learning Techniques,” in 2019 International Conference on Data Science and Engineering (ICDSE), IEEE, Sep. 2019, pp. 55–60. doi: 10.1109/ICDSE47409.2019.8971796.
A. Atçılı, O. Özkaraca, G. Sarıman, and B. Patrut, “Next Word Prediction with Deep Learning Models,” in Smart Applications with Advanced Machine Learning and Human-Centred Problem Design, 2023, pp. 523–531. doi: 10.1007/978-3-031-09753-9_38.
G. Singh and C. P. Kamboj, “Deep Learning for Predicting the Next Word in Bilingual Social Media Texts,” SN Comput. Sci., vol. 6, no. 54, 2024, doi: doi.org/10.1007/s42979-024-03585-8.
F. S. Al-Anzi and S. T. B. Shalini, “Revealing the Next Word and Character in Arabic: An Effective Blend of Long Short-Term Memory Networks and ARABERT,” Appl. Sci., vol. 14, no. 22, p. 10498, Nov. 2024, doi: 10.3390/app142210498.
A. Tiwari, N. Sengar, and V. Yadav, “Next Word Prediction Using Deep Learning,” in 2022 IEEE Global Conference on Computing, Power and Communication Technologies (GlobConPT), IEEE, Sep. 2022, pp. 1–6. doi: 10.1109/GlobConPT57482.2022.9938153.
F. LAHRACHE and S. DJEBRIT, “Next Word Prediction Based On De ep Learning,” University of Ghardaia, 2020. [Online]. Available: https://dspace.univ-ghardaia.edu.dz/xmlui/handle/123456789/366
A. Hoque, B. Jahan, S. C. Paul, Z. A. Zabu, R. Mondal, and P. Akter, “Next Words Prediction and Sentence Completion in Bangla Language Using GRU-Based RNN on N-Gram Language Model,” J. Data Anal. Inf. Process., vol. 11, no. 04, pp. 388–399, 2023, doi: 10.4236/jdaip.2023.114020.
Y. Ikegami, S. Tsuruta, A. Kutics, E. Damiani, and R. Knauf, “Fast ML-based next-word prediction for hybrid languages,” Internet of Things, vol. 25, p. 101064, Apr. 2024, doi: 10.1016/j.iot.2024.101064.
D. Gerz, I. Vulić, E. Ponti, J. Naradowsky, R. Reichart, and A. Korhonen, “Language Modeling for Morphologically Rich Languages: Character-Aware Modeling for Word-Level Prediction,” Trans. Assoc. Comput. Linguist., vol. 6, pp. 451–465, Dec. 2018, doi: 10.1162/tacl_a_00032.
M. H. Ahmad, A. Saeed, M. U. Bhatti, N. Hussain, M. F. Ullah, and M. Anwar, “Next Word Prediction for Urdu using Deep Learning Techniques,” VFAST Trans. Softw. Eng., vol. 13, no. 1, pp. 49–59, Feb. 2025, doi: 10.21015/vtse.v13i1.2044.
M. Mahbub, S. Akhter, A. Kabir, and Z. Begum, “Context-based Bengali Next Word Prediction: A Comparative Study of Different Embedding Methods,” Dhaka Univ. J. Appl. Sci. Eng., vol. 7, no. 2, 2022, doi: https://www.banglajol.info/index.php/DUJASE/article/view/65088/44180.
R. Shahid, A. Wali, and M. Bashir, “Next word prediction for Urdu language using deep learning models,” Comput. Speech Lang., vol. 87, p. 101635, Aug. 2024, doi: 10.1016/j.csl.2024.101635.
P. P. Barman and A. Boruah, “A RNN based Approach for next word prediction in Assamese Phonetic Transcription,” Procedia Comput. Sci., vol. 143, pp. 117–123, 2018, doi: 10.1016/j.procs.2018.10.359.
H. K. Hamarashid, S. A. Saeed, and T. A. Rashid, “Next word prediction based on the N-gram model for Kurdish Sorani and Kurmanji,” Neural Comput. Appl., vol. 33, no. 9, pp. 4547–4566, May 2021, doi: 10.1007/s00521-020-05245-3.
X. Liang, Z. Wang, M. Li, and Z. Yan, “A survey of LLM-augmented knowledge graph construction and application in complex product design,” Procedia CIRP, vol. 128, pp. 870–875, 2024, doi: 10.1016/j.procir.2024.07.069.
X. Cao and Y. Liu, “ReLMKG: reasoning with pre-trained language models and knowledge graphs for complex question answering,” Appl. Intell., vol. 53, no. 10, pp. 12032–12046, May 2023, doi: 10.1007/s10489-022-04123-w.
H. Chen, J. Dong, X. Huang, Z. Yu, D. Zha, and Q. Zhang, “KnowGPT: Knowledge Graph based Prompting for Large Language Models,” in Advances in Neural Information Processing Systems 37, San Diego, California, USA: Neural Information Processing Systems Foundation, Inc. (NeurIPS), 2024, pp. 6052–6080. doi: 10.52202/079017-0196.
M. Zhang, X. Ye, Q. Liu, P. Ren, S. Wu, and Z. Chen, “Knowledge Graph Enhanced Large Language Model Editing,” arXiv Prepr. arXiv2402.13593, 2024, doi: https://doi.org/10.48550/arXiv.2402.13593.
A. T. Magar and A. Shakya, “Next Word Suggestion using Graph Neural Network,” arXiv:2505.09649v1, 2025, doi: doi.org/10.48550/arXiv.2505.09649.
O. Einea, A. Elnagar, and R. Al-Debsi, “SANAD: Single-Label Arabic News Articles Dataset for Automatic Text Categorization,” Data Br., vol. 25, no. 2, 2019, doi: 10.17632/57zpx667y9.2.
W. Wu, C. Wen, Q. Yuan, Q. Chen, and Y. Cao, “Construction and application of knowledge graph for construction accidents based on deep learning,” Eng. Constr. Archit. Manag., vol. 32, no. 2, pp. 1097–1121, Feb. 2025, doi: 10.1108/ECAM-03-2023-0255.
M. Dehghan et al., “EWEK-QA : Enhanced Web and Efficient Knowledge Graph Retrieval for Citation-based Question Answering Systems,” in Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Stroudsburg, PA, USA: Association for Computational Linguistics, 2024, pp. 14169–14187. doi: 10.18653/v1/2024.acl-long.764.
M. Rotmensch, Y. Halpern, A. Tlimat, S. Horng, and D. Sontag, “Learning a Health Knowledge Graph from Electronic Medical Records,” Sci. Rep., vol. 7, no. 1, p. 5994, Jul. 2017, doi: 10.1038/s41598-017-05778-z.
K. K. Teru, E. G. Denis, and W. L. Hamilton, “Inductive relation prediction by subgraph reasoning,” 37th Int. Conf. Mach. Learn. ICML 2020, vol. PartF16814, no. 1, pp. 9390–9399, 2020.
W. Antoun, F. Baly, and H. Hajj, “AraBERT: Transformer-based Model for Arabic Language Understanding,” in LREC 2020 Workshop Language Resources and Evaluation Conference 11--16 May 2020, 2020, p. 9.
W. Antoun, F. Baly, and H. Hajj, “ARAGPT2: Pre-Trained Transformer for Arabic Language Generation,” Proc. sixth Arab. Nat. Lang. Process. Work., pp. 196–207, 2021, doi: arXiv:2012.15520.
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2026 Noralhuda N. Alabid

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.




