From Pixels to Sentence: A Comprehensive Study of Transformers-Based Models for Image Captioning
DOI:
https://doi.org/10.29304/jqcsm.2026.18.12477Keywords:
Image Captioning, Transformers, Vision-Language Models, Multimodal Learning, Deep LearningAbstract
The task of image captioning, which involves generating descriptive textual content from visual input, is a pivotal challenge in multimodal learning. This research delves into the advancements in image captioning facilitated by Transformer-based models, comparing their performance, architectures, and innovations across various tasks. Traditional models, such as CNNs paired with RNNs, were initially used to extract visual features and generate corresponding captions. However, the introduction of Transformer architectures has significantly enhanced the performance of image captioning systems, allowing for more coherent, context-aware, and grammatically correct captions. This paper explores the evolution of Transformer-based models, with a particular focus on the Encoder-Decoder, Vision-Language Fusion, and End-to-End Transformers models. By analyzing state-of-the-art architectures such as ViT, GPT, BLIP, and CoCa, the study demonstrates how these models address long-range dependencies, utilize self-attention mechanisms, and seamlessly integrate vision and language for improved caption generation. Furthermore, the paper evaluates the strengths, challenges, and limitations of these approaches, including issues related to computational complexity, dataset biases, and caption diversity. Ultimately, this study presents a comprehensive comparison of these models, offering insights into future research directions in the field of image captioning.
Downloads
References
F. Bianchi et al., “Easily accessible text-to-image generation amplifies demographic stereotypes at large scale,” in Proc. ACM Conf. Fairness, Accountability, and Transparency (FAccT), 2023, pp. 1493–1504.
B.-K. Ruan, H.-H. Shuai, and W.-H. Cheng, “Vision transformers: State of the art and research challenges,” arXiv preprint arXiv:2207.03041, 2022.
P. Chun, T. Yamane, and Y. Maemura, “A deep learning‐based image captioning method to automatically generate comprehensive explanations of bridge damage,” Comput.-Aided Civ. Infrastruct. Eng., vol. 37, no. 11, pp. 1387–1401, 2022.
A. Vaswani et al., “Attention is all you need,” in Adv. Neural Inf. Process. Syst. (NeurIPS), 2017, pp. 5998–6008.
Y. Gorishniy, I. Rubachev, and A. Babenko, “On embeddings for numerical features in tabular deep learning,” in Adv. Neural Inf. Process. Syst. (NeurIPS), vol. 35, 2022, pp. 24991–25004.
S. Islam et al., “A comprehensive survey on applications of transformers for deep learning tasks,” Expert Syst. Appl., vol. 241, p. 122666, 2024.
J. Kim, H. Kang, and P. Kang, “Time-series anomaly detection with stacked Transformer representations and 1D convolutional network,” Eng. Appl. Artif. Intell., vol. 120, p. 105964, 2023.
Z. Wu, H. Zhang, P. Wang, and Z. Sun, “RTIDS: A robust transformer-based approach for intrusion detection system,” IEEE Access, vol. 10, pp. 64375–64387, 2022.
J. Li, D. Li, C. Xiong, and S. Hoi, “BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation,” in Proc. Int. Conf. Mach. Learn. (ICML), 2022, pp. 12888–12900.
Z. Wang et al., “SimVLM: Simple visual language model pretraining with weak supervision,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2022.
Y.-C. Chen et al., “UNITER: Universal image-text representation learning,” in Proc. Eur. Conf. Comput. Vis. (ECCV), 2020, pp. 104–120.
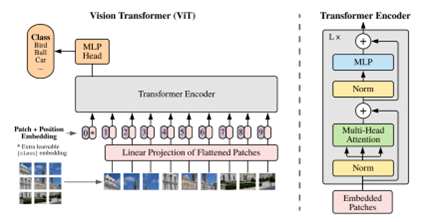
A. Dosovitskiy et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2021.
H. Liu et al., “Visual instruction tuning,” in Adv. Neural Inf. Process. Syst. (NeurIPS), 2023.
M. Al-Mallas et al., “The power of pretraining in multimodal vision-language models,” IEEE Trans. Artif. Intell., 2023.
A. Dosovitskiy et al., “Discriminative unsupervised feature learning with exemplar convolutional neural networks,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 38, no. 9, pp. 1734–1747, 2016.
A. Dosovitskiy et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” arXiv preprint arXiv:2010.11929, 2020.
A. Dosovitskiy, P. Fischer, J. T. Springenberg, M. Riedmiller, and T. Brox, “Discriminative unsupervised feature learning with exemplar convolutional neural networks,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2015, pp. 1050–1057.
K. Han et al., “A survey on vision transformer,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 1, pp. 87–110, 2022.
W. Liu et al., “CPTR: Full transformer network for image captioning,” arXiv preprint arXiv:2101.10804, 2021.
M. Raghu et al., “Do vision transformers see like convolutional neural networks?,” in Adv. Neural Inf. Process. Syst. (NeurIPS), 2021.
S. Khan et al., “Transformers in vision: A survey,” ACM Comput. Surv., vol. 54, no. 10s, pp. 1–41, 2022.
S. H. Lee, S. Lee, and B. C. Song, “Vision transformer for small-size datasets,” arXiv preprint arXiv:2112.13492, 2021.
X. Zhai et al., “Scaling vision transformers,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2022, pp. 12104–12113.
T. Brown et al., “Language models are few-shot learners,” in Adv. Neural Inf. Process. Syst. (NeurIPS), 2020, pp. 1877–1901.
Y. Bengio, A. Courville, and P. Vincent, “Representation learning: A review and new perspectives,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 35, no. 8, pp. 1798–1828, 2013.
L. Ouyang et al., “Training language models to follow instructions with human feedback,” in Adv. Neural Inf. Process. Syst. (NeurIPS), 2022.
Z. Gan et al., “Playing lottery tickets with vision and language,” in Proc. AAAI Conf. Artif. Intell., 2021.
M. Lee, “A mathematical investigation of hallucination and creativity in GPT models,” Mathematics, vol. 11, no. 10, p. 2320, 2023.
P. Zhang et al., “VinVL: Revisiting visual representations in vision-language models,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2021.
S. Dhamala et al., “Bold: Dataset and metrics for measuring biases in open-ended language generation,” in Proc. ACM Conf. Fairness, Accountability, and Transparency, 2021.
S. He et al., “Image captioning through image transformer,” in Proc. Eur. Conf. Comput. Vis. (ECCV), 2020.
Z. Wang et al., “SimVLM: Simple visual language model pretraining with weak supervision,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2022.
M. Cornia, M. Stefanini, L. Baraldi, and R. Cucchiara, “Meshed-memory transformer for image captioning,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2020, pp. 10578–10587.
M. Cornia et al., “Meshed-memory transformer for image captioning,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2020, pp. 10578–10587.
J. Lu et al., “ViLBERT: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks,” in Adv. Neural Inf. Process. Syst. (NeurIPS), 2019.
F. Zhou, Y. Liu, and Y. Wu, “A survey of vision-language models and their applications,” IEEE Trans. Neural Netw. Learn. Syst., 2023.
Y. Liu et al., “CPTR: Full transformer network for image captioning,” arXiv preprint arXiv:2101.10804, 2021.
H. Zhang et al., “Scene graph generation with external knowledge and image reconstruction,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2019.
X. Li, X. Yin, C. Li, P. Zhang, X. Hu, and L. Zhang, “Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks,” in ECCV, 2020.
P. Anderson et al., “Bottom-up and top-down attention for image captioning and visual question answering,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2018.
L. H. Li et al., “VisualBERT: A simple and performant baseline for vision and language,” arXiv preprint arXiv:1908.03557, 2019.
R. Zellers et al., “From recognition to cognition: Visual commonsense reasoning,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2019.
M. Guo et al., “Normalized and geometry-aware self-attention network for image captioning,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2020.
L. Zhang et al., “Grid-based image-text transformer for vision-language tasks,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2021.
T. Wang et al., “Vision-language models for multimodal tasks: A survey,” IEEE Trans. Multimedia, 2023.
C. Yang et al., “Empirical study of zero-shot transfer learning of CLIP models,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2021.
U. Naseem, S. Thapa, and A. Masood, “Advancing accuracy in multimodal medical tasks through bootstrapped language-image pretraining (BioMedBLIP): Performance evaluation study,” JMIR Med. Inform., vol. 12, p. e56627, 2024.
Y. Zeng et al., “X-Linear attention networks for image captioning,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2020.
J. Li et al., “BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation,” in Proc. Int. Conf. Mach. Learn. (ICML), 2022.
P. Tang et al., “Visual grounding with transformers,” IEEE Trans. Neural Netw. Learn. Syst., 2023.
L. M. et al., “Improved multimodal captioning with bootstrapped pretraining,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2022.
F. Zhang et al., “Multimodal pretraining for vision and language: A survey,” IEEE Trans. Artif. Intell., 2023.
W. Kim et al., “ViLT: Vision-and-language transformer without convolution or region supervision,” in Proc. Int. Conf. Mach. Learn. (ICML), 2021.
P. Zhang et al., “VinVL: Revisiting visual representations in vision-language models,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2021, pp. 5579–5588.
X. Li et al., “XiVL: Embedding-based cross-modal integration for vision-language pre-training,” IEEE Trans. Neural Netw. Learn. Syst., 2022.
X. Li et al., “M6: A chinese multimodal pretrainer,” arXiv preprint arXiv:2103.00823, 2021.
D. Bui, T. Nguyen, and K. Nguyen, “Transformer with multi-level grid features and depth pooling for image captioning,” Mach. Vis. Appl., vol. 35, 2024.
A. Radford et al., “Learning transferable visual models from natural language supervision,” arXiv preprint arXiv:2103.00020, 2021.
S. Zhang et al., “Vision-text fusion for image captioning with enhanced visual encodings,” IEEE Trans. Artif. Intell., 2023.
Stanford University, “Multi-modal image captioning with transformer-based unified architecture,” CS224N Final Report, 2021.
Y. Xu, Y. Luo, R. Zhang, and J. Ma, “A frustratingly simple approach for end-to-end image captioning,” arXiv preprint arXiv:2201.12723, 2022.
Z. Liu et al., “Swin transformer: Hierarchical vision transformer using shifted windows,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2021.
R. Zhang et al., “Multimodal fusion and attention mechanisms for end-to-end image captioning,” IEEE Trans. Artif. Intell., 2023.
T. Chen et al., “Pix2seq: A language modeling framework for object detection,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2022.
J. Xu, Y. Wang, and Y. Sun, “End-to-end transformer based model for image captioning,” arXiv preprint arXiv:2203.15350, 2022.
X. Li et al., “Contrastive learning for vision-language tasks,” IEEE Trans. Neural Netw. Learn. Syst., 2022.
J. Yu, Z. Wang, V. Vasudevan, and L. Yeung, “CoCa: Contrastive captioners are image-text foundation models,” arXiv preprint arXiv:2205.01917, 2022.
A. Li et al., “Enhancing image captioning with contrastive learning: A survey,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2022.
W. Zhao et al., “Improved image-text matching and generation with contrastive learning,” IEEE Trans. Pattern Anal. Mach. Intell., 2023.
M. T. et al., “The power of contrastive learning for multimodal understanding,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), 2021.
F. Zhang et al., “Leveraging contrastive loss for multimodal generation tasks,” IEEE Trans. Image Process., 2022.
A. P. et al., “Improving image captioning with contrastive attention models,” IEEE Trans. Comput. Vis. Image Underst., 2023.
P. Chen et al., “Contrastive learning for vision and language tasks: A survey,” IEEE Trans. Neural Netw. Learn. Syst., 2022.
S. Khan et al., “Contrastive learning for visual representation and captioning,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2022.
D. Li et al., “Learning to rank contrastive image-caption pairs for multimodal retrieval,” IEEE Trans. Artif. Intell., 2022.
T. Zhang et al., “Visualizing and understanding CLIP: A survey,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2022.
M. R. et al., “CLIP: Contrastive language-image pretraining for zero-shot vision-language tasks,” IEEE Trans. Artif. Intell., 2022.
OpenAI. (2021). CLIP: Connecting text and images. [Online]. Available: https://openai.com/index/clip/
P. Zhang et al., “Enhancing image-text matching using contrastive learning,” IEEE Trans. Neural Netw. Learn. Syst., vol. 34, no. 2, pp. 45–58, 2023.
Y. Liu et al., “Contrastive pretraining for vision-language models,” IEEE Trans. Image Process., 2022.
Z. Wang et al., “CLIP for visual-textual alignment: Applications and performance,” IEEE Trans. Artif. Intell., 2023.
C. Jia et al., “ALIGN: Scaling up visual and vision-language representation learning with noisy text supervision,” in Proc. Int. Conf. Mach. Learn. (ICML), 2021, pp. 4904–4916.
J. Li et al., “Contrastive learning for vision-language models with noisy data,” IEEE Trans. Neural Netw. Learn. Syst., 2022.
C. Jia et al., “Scaling up visual and vision-language representation learning with noisy text supervision,” in Proc. Int. Conf. Mach. Learn. (ICML), 2021.
S. Khan et al., “Contrastive pretraining for vision-language models with ALIGN,” IEEE Trans. Neural Netw. Learn. Syst., 2023.
J. Zhang et al., “ALIGN: Vision-language pretraining with large-scale noisy data,” IEEE Trans. Neural Netw. Learn. Syst., 2023.
Y. Li et al., “Exploring vision-language models for image captioning with ALIGN,” IEEE Trans. Multimedia, 2023.
R. Luo, “Goal-driven text descriptions for images,” arXiv preprint arXiv:2108.12575, 2021.
D. Sharma, C. Dhiman, and D. Kumar, “Evolution of visual data captioning methods, datasets, and evaluation metrics: A comprehensive survey,” Expert Syst. Appl., vol. 221, p. 119773, 2023.
M. Tsukiyama and K. Aizawa, “Visual question answering,” Int. J. Adv. Eng. Manag., vol. 2, pp. 63–75, 2020.
Z. Shi, X. Zhou, X. Qiu, and X. Zhu, “Improving image captioning with better use of captions,” arXiv preprint arXiv:2006.11807, 2020.
A. Ghosh, D. Dutta, and T. Moitra, “A neural network framework to generate caption from images,” in Emerging Technology in Modelling and Graphics, 2020, pp. 171–180.
S. Takkar, A. Jain, and P. Adlakha, “Comparative study of different image captioning models,” in Proc. 5th Int. Conf. Comput. Methodol. Commun. (ICCMC), 2021, pp. 1366–1371.
Adityajn, “Flickr8k Dataset.” Accessed: Oct. 10, 2025. [Online]. Available: https://www.kaggle.com/datasets/adityajn105/flickr8k.
S. Changpinyo, P. Sharma, N. Ding, and R. Soricut, “Conceptual 12M: Pushing web-scale image-text pre-training to recognize long-tail visual concepts,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2021, pp. 3558–3568.
G. Luo, L. Cheng, C. Jing, C. Zhao, and G. Song, “A thorough review of models, evaluation metrics, and datasets on image captioning,” IET Image Process., vol. 16, no. 2, pp. 311–332, 2022.
M. S. Wajid, H. Terashima‐Marin, P. Najafirad, and M. A. Wajid, “Deep learning and knowledge graph for image/video captioning: A review,” Eng. Reports, vol. 6, no. 1, p. e12785, 2024.
kaggle, “Flickr30k website,” 2021, [Online]. Available: https://www.kaggle.com/datasets/eeshawn/flickr30k.
S. Chun, W. Kim, S. Park, M. Chang, and S. J. Oh, “ECCV Caption: Correcting false negatives by collecting machine-and-human-verified image-caption associations for MS-COCO,” in Proc. Eur. Conf. Comput. Vis. (ECCV), 2022, pp. 1–19.
X. Mao et al., “COCO-O: A benchmark for object detectors under natural distribution shifts,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2023, pp. 6339–6350.
N. Sharif et al., “Vision to language: Methods, metrics and datasets,” in Machine Learning Paradigms, 2020, pp. 9–62.
MS-COCO Official, “MS-COCO Dataset.” Accessed: Oct. 10, 2025. [Online]. Available: https://cocodataset.org/#download.
S. K. Mishra, Harshit, S. Saha, and P. Bhattacharyya, “An object localization-based dense image captioning framework in Hindi,” ACM Trans. Asian Low-Resource Lang. Inf. Process., vol. 22, no. 2, pp. 1–15, 2022.
O. Sidorov, R. Hu, M. Rohrbach, and A. Singh, “TextCaps: A dataset for image captioning with reading comprehension,” in Proc. Eur. Conf. Comput. Vis. (ECCV), 2020, pp. 742–758.
R. Munro, Human-in-the-Loop Machine Learning: Active learning and annotation for human-centered AI. Manning, 2021.
R. Krishna et al., “Visual Genome: Connecting language and vision using crowdsourced dense image annotations,” Int. J. Comput. Vis., vol. 123, no. 1, pp. 32–73, 2017.
D. A. Chacra and J. Zelek, “The topology and language of relationships in the visual genome dataset,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. Workshops (CVPRW), 2022, pp. 4859–4867.
Q. Wang, J. Wan, and A. B. Chan, “On diversity in image captioning: Metrics and methods,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 44, no. 2, pp. 1035–1049, 2020.
S. Chauhan and P. Daniel, “A comprehensive survey on various fully automatic machine translation evaluation metrics,” Neural Process. Lett., vol. 55, no. 9, pp. 12663–12717, 2023.
A. B. Mitta et al., “Comparative analysis on machine learning models for image captions generation,” in Proc. 4th Int. Conf. Smart Electron. Commun. (ICOSEC), 2023, pp. 1011–1017.
J. Hessel, A. Holtzman, M. Forbes, R. Le Bras, and Y. Choi, “CLIPScore: A reference-free evaluation metric for image captioning,” arXiv preprint arXiv:2104.08718, 2021.
S. Jaiswal et al., “An extensive analysis of image captioning models, evaluation measures, and datasets,” Int. J. Multidiscip. Sci. Res. Rev., vol. 1, no. 01, pp. 21–37, 2023.
D. M. Chan et al., “What’s in a caption? Dataset-specific linguistic diversity and its effect on visual description models and metrics,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2022, pp. 4740–4749.
Z. Wang, Z. Huang, and Y. Luo, “Human consensus-oriented image captioning,” in Proc. Int. Jt. Conf. Artif. Intell. (IJCAI), 2021, pp. 659–665.
S. Kumar and A. Solanki, “ROUGE-SS: A new ROUGE variant for evaluation of text summarization,” Authorea Preprints, 2023.
M. Barbella and G. Tortora, “ROUGE metric evaluation for text summarization techniques,” SSRN Electronic Journal, 2022.
S. Sotudeh and N. Goharian, “Learning to rank salient content for query-focused summarization,” arXiv preprint arXiv:2411.00324, 2024.
K. Blagec et al., “A critical analysis of metrics used for measuring progress in artificial intelligence,” arXiv preprint arXiv:2008.02577, 2020.
Y. Wada, K. Kaneda, and K. Sugiura, “JaSPICE: Automatic evaluation metric using predicate-argument structures for image captioning models,” arXiv preprint arXiv:2311.04192, 2023.
U. Sirisha and B. Sai Chandana, “Semantic interdisciplinary evaluation of image captioning models,” Cogent Eng., vol. 9, no. 1, p. 2104333, 2022.
A. de Souza Inácio and H. S. Lopes, “Evaluation metrics for video captioning: A survey,” Mach. Learn. with Appl., vol. 13, p. 100488, 2023.
Y. Pan et al., “X-LAN: Cross-lingual attention network for image captioning,” in Proc. AAAI Conf. Artif. Intell., 2020, pp. 11786–11793.
P. Zhang et al., “VinVL: Revisiting visual representations in vision-language models,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2021.
L. Guo et al., “Entity-relation self-attention network for image captioning,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2021, pp. 1242–1251.
A. Radford et al., “CLIP: Connecting text and images with contrastive learning,” OpenAI Blog, 2021.
Z. Yuan et al., “VIVO: Visual vocabulary transformer for image captioning,” in Proc. AAAI Conf. Artif. Intell., 2021, pp. 3215–3223.
J. Wang et al., “GIT: A generative image-to-text transformer for vision and language,” in Adv. Neural Inf. Process. Syst. (NeurIPS), 2022.
Z. Wang et al., “SimVLM: Simple visual language model pretraining with weak supervision,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2022.
J. Yu et al., “CoCa: Contrastive captioners are image-text foundation models,” in Adv. Neural Inf. Process. Syst. (NeurIPS), 2022.
Y. Zhou et al., “Dual-level collaborative transformer for image captioning,” in Proc. Eur. Conf. Comput. Vis. (ECCV), 2022.
T. S. Nguyen et al., “GRIT: Grid-based image-text transformer for vision-language tasks,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2022.
W. Wang et al., “Image as a foreign language: BEiT pretraining for all vision and vision-language tasks,” in Adv. Neural Inf. Process. Syst. (NeurIPS), 2022.
H. Liu, C. Li, Q. Wu, and Y. J. Lee, “Visual instruction tuning,” in Adv. Neural Inf. Process. Syst. (NeurIPS), 2023.
W. Dai et al., “InstructBLIP: Towards general-purpose vision-language models with instruction tuning,” in Adv. Neural Inf. Process. Syst. (NeurIPS), 2023.
X. Chen et al., “PaLI-X: Scaling language-image learning with pathways,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2023.
Q. Ye et al., “mPLUG-Owl: Modularization empowers large language models with multimodality,” arXiv preprint arXiv:2304.14178, 2023.
S. Huang et al., “Language is not all you need: Aligning perception with language models,” in Adv. Neural Inf. Process. Syst. (NeurIPS), 2023. (Kosmos-1).
R. Zhu et al., “VisionGPT: A generative pretrained transformer for vision-language tasks,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), 2023.
J.-B. Alayrac et al., “Flamingo: A visual language model for few-shot learning,” in Adv. Neural Inf. Process. Syst. (NeurIPS), 2022.
J. Li et al., “BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models,” in Proc. Int. Conf. Mach. Learn. (ICML), 2023.
D. Zhu et al., “MiniGPT-4: Enhancing vision-language understanding with advanced large language models,” arXiv preprint arXiv:2304.10592, 2023.
A. Awadalla et al., “OpenFlamingo: An open-source framework for training multimodal models,” arXiv preprint arXiv:2308.01390, 2023.
B. Chen et al., “X-LLM: Bootstrapping advanced large language models by treating multi-modalities as foreign languages,” in Proc. Empir. Methods Nat. Lang. Process. (EMNLP), 2023.
W. Wang et al., “VisionLLM: Large language model is also an open-ended decoder for FPGA-accelerated vision-centric tasks,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), 2023.
R. Zhang et al., “LLaMA-Adapter: Efficient fine-tuning of language models with zero-init attention,” arXiv preprint arXiv:2303.16199, 2023.
J. Bai et al., “Qwen-VL: A versatile vision-language model for understanding, localization, text reading, and beyond,” arXiv preprint arXiv:2308.12966, 2023.
OpenAI, “GPT-4 technical report,” arXiv preprint arXiv:2303.08774, 2023.
Gemini Team, Google, “Gemini: A family of multimodal generative models,” arXiv preprint arXiv:2312.11805, 2023.
R. Zhang et al., “VisionGPT-2: Enhanced vision-language transformer with dynamic attention,” arXiv preprint arXiv:2401.02345, 2024.
S. Huang et al., “Kosmos-2.5: A multimodal literate model,” arXiv preprint arXiv:2309.11419, 2023.
X. Chen et al., “PaLI-3 vision language models: Smaller, faster, stronger,” arXiv preprint arXiv:2310.09199, 2023.
H. Liu et al., “LLaVA-Next: Improved visual instruction tuning,” arXiv preprint arXiv:2403.11712, 2024.
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2026 Haider Jaber Samawi, Ayad Rodhan Abbas

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.




