Software Defect Prediction with a Stacking Ensemble Model
DOI:
https://doi.org/10.29304/jqcsm.2026.18.22616Keywords:
Ensemble learning, Software defect prediction, Software quality, Machine Learning.Abstract
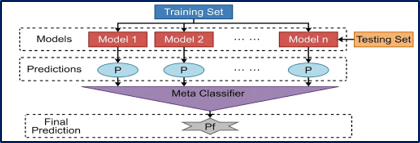
Software plays a critical role in modern systems, making defect prediction an essential task in software engineering. in all aspects of life, including in the industrial and medical fields, as designing reliable and high-quality software is considered one of the most important aspects of daily life to avoid potential risks, for example, financial and human, resulting from software errors, as they are considered a major challenge in terms of time and budget. Therefore, many companies have adopted and paid attention to developing their own software in terms of employing computer science, including its own algorithms, including algorithms that use machine learning to predict and detect these errors by using previous project records that contain the required data. This approach makes decision-making more accurate and effective in improving software performance and security. In our study, the use of ensemble machine learning was proposed, the purpose of which is to build a model to predict errors, as this approach helps in increasing the accuracy of prediction due to the diversity of data used... as well as improving the performance of defect classification models by using ensemble learning techniques based on the principle of stacking. In our work, we used the process of a combination among base learning algorithms (Bagging, Gradient Boosting, and CatBoost) and then fed into a meta learning algorithm such as XGBoost, in each dataset loaded containing a set of features and a target column called "Defective" that specifies whether the sample is defective or not. All possible combinations of these models (duplexes, triples) are generated and combined into a higher-order ensemble model known as a stacking classifier. In this context, NASA's MDP data warehouse, which specializes in defect prediction, was used, for feature selection and dataset balancing. The defect prediction was then evaluated, and evaluation metrics (accuracy, precision, recall, and F1 score) were calculated. The proposed model was executed with the help of the stacking method on the dataset that was used.
Downloads
References
T. Zhang, Q. Du, J. Xu, J. Li, and X. Li, “Software defect prediction and localization with attention-based models and ensemble learning,” Proc. - Asia-Pacific Softw. Eng. Conf. APSEC, vol. 2020-Decem, pp. 81–90, 2020, doi: 10.1109/APSEC51365.2020.00016.
T. Menzies, R. Krishna, and D. Pryor, “e Promise Repository of Empirical So ware Engineering Data. hp,” openscience. us/repo. North Carolina State Univ. Dep. Comput. Sci., 2015.
R. Malhotra, “A systematic review of machine learning techniques for software fault prediction,” Appl. Soft Comput., vol. 27, pp. 504–518, 2015.
A. Iqbal, S. Aftab, I. Ullah, M. S. Bashir, and M. A. Saeed, “A feature selection based ensemble classification framework for software defect prediction,” Int. J. Mod. Educ. Comput. Sci., vol. 11, no. 9, p. 54, 2019.
T. T. Khuat and M. H. Le, “Evaluation of sampling-based ensembles of classifiers on imbalanced data for software defect prediction problems,” SN Comput. Sci., vol. 1, no. 2, p. 108, 2020.
P. Suresh Kumar, H. S. Behera, J. Nayak, and B. Naik, “Bootstrap aggregation ensemble learning-based reliable approach for software defect prediction by using characterized code feature,” Innov. Syst. Softw. Eng., vol. 17, no. 4, pp. 355–379, 2021.
A. Ali, N. Khan, M. Abu-Tair, J. Noppen, S. McClean, and I. McChesney, “Discriminating features-based cost-sensitive approach for software defect prediction,” Autom. Softw. Eng., vol. 28, pp. 1–18, 2021.
Z. Yang, C. Jin, Y. Zhang, J. Wang, B. Yuan, and H. Li, “Software Defect prediction: An Ensemble Learning Approach,” in Journal of Physics: Conference Series, 2022, vol. 2171, no. 1, p. 12008.
A. M. Ibrahim, H. Abdelsalam, and I. A. T. F. Taj-Eddin, “Software Defects Prediction At Method Level Using Ensemble Learning Techniques,” Int. J. Intell. Comput. Inf. Sci., vol. 23, no. 2, pp. 28–49, 2023.
H. M and S. M.N, “A Review on Evaluation Metrics for Data Classification Evaluations,” Int. J. Data Min. Knowl. Manag. Process, vol. 5, no. 2, pp. 01–11, 2015, doi: 10.5121/ijdkp.2015.5201.
N. Ahmad Alawad and N. Ghani Rahman, “Design of (FPID) controller for Automatic Voltage Regulator using Differential Evolution Algorithm,” Int. J. Mod. Educ. Comput. Sci., vol. 11, no. 12, pp. 21–28, 2019, doi: 10.5815/ijmecs.2019.12.02.
N. Monga and P. Sehgal, “An Extensive Study of Various Software Defect prediction Techniques,” NeuroQuantology, vol. 20, no. 14, pp. 291–302, 2022, doi: 10.4704/nq.2022.20.14.
P. Bühlmann and B. Yu, “Analyzing bagging,” The Annals of Statistics, vol. 30, no. 4, pp. 927–961, 2002.
C. Bentéjac, A. Csörgő, and G. Martínez-Muñoz, “A comparative analysis of Gradient Boosting algorithms,” Artificial Intelligence Review, vol. 54, no. 3, pp. 1937–1967, 2021.
L. Prokhorenkova, G. Gusev, A. Vorobev, A. V. Dorogush, and A. Gulin, “CatBoost: unbiased boosting with categorical features,” in Advances in Neural Information Processing Systems, vol. 31, 2018.
M. Nalluri, M. Pentela, and N. R. Eluri, “A scalable tree boosting system: XGBoost,” Int. J. Res. Stud. Sci. Eng. Technol., vol. 7, no. 12, pp. 36–51, 2020.
N. Kussul, M. Lavreniuk, S. Skakun, and A. Shelestov, “Deep Learning Classification of Land Cover and Crop Types Using Remote Sensing Data,” IEEE Geosci. Remote Sens. Lett., vol. 14, no. 5, pp. 778–782, 2017, doi: 10.1109/LGRS.2017.2681128.
S. A. Case, H. Zhao, Z. Chen, H. Jiang, W. Jing, and L. Sun, “Evaluation of Three Deep Learning Models for Early Crop Classification Using Sentinel-1A Imagery Time,” Remote Sens, vol. 11, no. 2673, pp. 1–23, 2019.
J. August, I. No, and A. Sharma, “Available Online at www.ijarcs.info International Journal of Advanced Research in Computer Science A RESEARCH REVIEW ON COMPARATIVE ANALYSIS OF DATA MINING TOOLS , TECHNIQUES AND PARAMETERS,” Int. J. Adv. Res. Comput. Sci., vol. 8, no. 7, pp. 523–529, 2017.
C. W. Yohannese, T. Li, M. Simfukwe, and F. Khurshid, “Ensembles Based Combined Learning for Improved Software Fault Prediction : A Comparative Study,” 2017 12th Int. Conf. Intell. Syst. Knowl. Eng. Ensembles, 2017.
F. Matloob et al., “Software defect prediction using ensemble learning: A systematic literature review,” IEEE Access, vol. 9, pp. 98754–98771, 2021, doi: 10.1109/ACCESS.2021.3095559.
Y. Xia, K. Chen, and Y. Yang, “Multi-label classification with weighted classifier selection and stacked ensemble,” Inf. Sci. (Ny)., vol. 557, pp. 421–442, 2021.
S. Antonik and B. Bąba, “Stacked Generalization—Investigating the impact on predictive performance of basic machine learning models,” vol. 3885, p. 49, 2024.
C. Giraud-Carrier, “Combining base-learners into ensembles,” in METALEARNING: APPLICATIONS TO AUTOMATED MACHINE LEARNING AND DATA MINING, Cham: Springer International Publishing, pp. 169–188, 2022.
S. Huda et al., “An ensemble oversampling model for class imbalance problem in software defect prediction,” IEEE access, vol. 6, pp. 24184–24195, 2018.
R. Mousavi, M. Eftekhari, and F. Rahdari, “Omni-ensemble learning (OEL): utilizing over-bagging, static and dynamic ensemble selection approaches for software defect prediction,” Int. J. Artif. Intell. Tools, vol. 27, no. 06, p. 1850024, 2018.
T. Chakraborty and A. K. Chakraborty, “Hellinger net: a hybrid imbalance learning model to improve software defect prediction,” IEEE Trans. Reliab., vol. 70, no. 2, pp. 481–494, 2020.
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2026 Maher F. Ismael

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.




